Промпт-инжиниринг / Техники промптинга
ReAct Prompting: как заставить нейросеть думать и действовать¶
Представьте, что вы даете нейросети сложную задачу, где недостаточно просто знать факты - нужно уметь их искать, анализировать и планировать действия. Классический метод Chain-of-Thought (CoT), когда модель шаг за шагом рассуждает, здесь часто спотыкается: нейросеть начинает "галлюцинировать", придумывать несуществующие данные. Решение предложили исследователи в 2022 году: фреймворк ReAct, который заставляет модель не только думать, но и действовать - например, искать информацию в интернете или базе данных. В этой статье разберем, как работает ReAct Prompting и как его применять на практике.
Что такое ReAct и как он работает?¶
ReAct (Reasoning + Acting) - это подход к промпт-инжинирингу, при котором большая языковая модель (LLM) генерирует не просто ответ, а целую траекторию решения: рассуждения (Thoughts) и действия (Actions). Действия позволяют модели взаимодействовать с внешним миром: выполнять поиск в Google, делать запросы к API или базе данных. Наблюдения (Observations) - это результаты этих действий. Затем модель анализирует наблюдения, корректирует план и продолжает.
Проще говоря, ReAct имитирует человеческое поведение: сначала подумал, потом сделал, посмотрел на результат, снова подумал. Это особенно полезно для задач, где нужны актуальные данные или многошаговое планирование.

Источник изображения: Yao и др., 2022
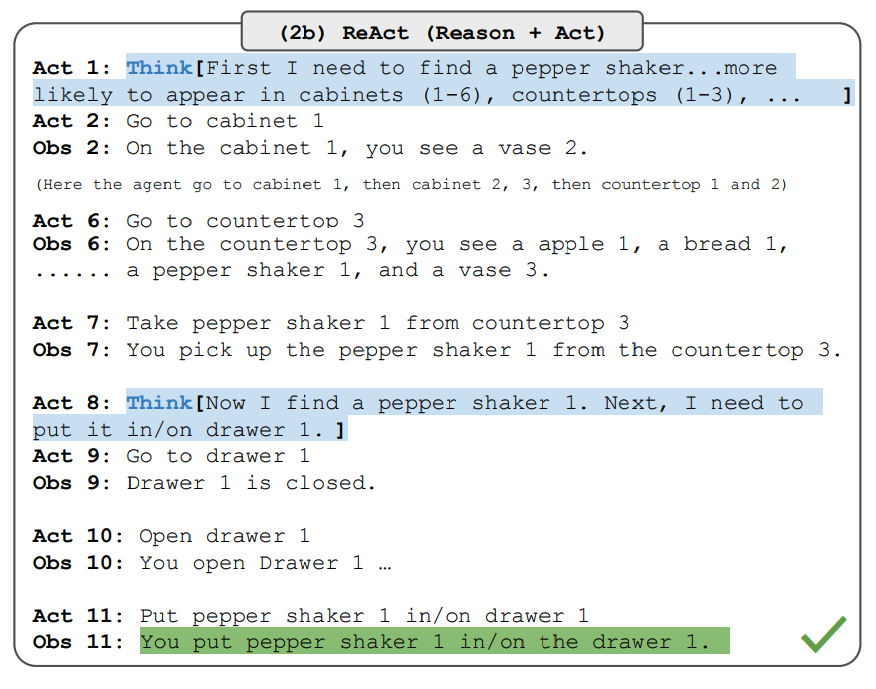
На схеме выше показан пример работы ReAct на вопрос из датасета HotpotQA: "Помимо Apple Remote, какие еще устройства могут управлять программой, для взаимодействия с которой изначально был разработан Apple Remote?". Модель не пытается ответить сразу из памяти. Она планирует: "Мне нужно найти, что такое Apple Remote, затем понять, для какой программы он создан, а потом искать другие устройства управления". Далее она выполняет действия поиска (Search), получает информацию и на ее основе формулирует финальный ответ.
Как выглядит промпт в стиле ReAct?¶
Чтобы обучить модель работать по схеме ReAct, в промпт включают несколько примеров (few-shot) с уже готовыми траекториями "Мысль-Действие-Наблюдение". Вот сокращенный пример из оригинальной статьи:
Промпт:
Question What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up eastern
sector.
Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called
the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So I
need to search High Plains and find its elevation range.
Action 3 Search[High Plains]
Observation 3 High Plains refers to one of two distinct land regions
Thought 4 I need to instead search High Plains (United States).
Action 4 Search[High Plains (United States)]
Observation 4 The High Plains are a subregion of the Great Plains. From east to west, the
High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130
m).[3]
Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer
is 1,800 to 7,000 ft.
Action 5 Finish[1,800 to 7,000 ft]
Ответ модели: Модель, следуя этому шаблону, для нового вопроса будет генерировать аналогичную цепочку.
Ключевое - формат. Для разных задач он может меняться. В задачах, где важно именно рассуждение (как в HotpotQA), мысли подробные. В задачах, где много действий (например, в текстовой игре), мысли могут быть краткими или вообще отсутствовать.
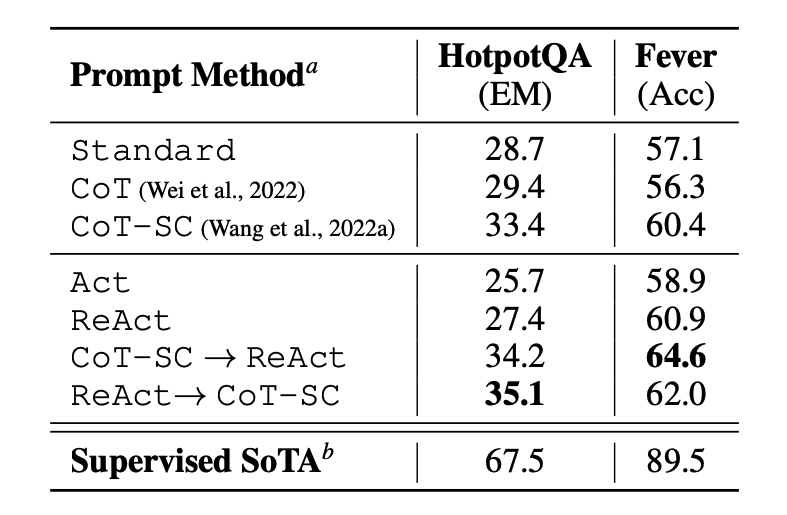
Насколько ReAct эффективен? Результаты исследований¶
Авторы протестировали ReAct на двух типах задач: требующих знаний (как вопрос-ответ) и требующих принятия решений (как игра или онлайн-шопинг).
На задачах вроде HotPotQA и Fever (проверка фактов) ReAct в среднем показал себя лучше, чем подход, где модель только действует без рассуждений (Act-only). Однако по сравнению с чистым CoT (только рассуждения) результаты смешанные. На Fever ReAct выиграл, а на HotPotQA - немного проиграл. Почему?
Источник изображения: Yao и др., 2022
Анализ ошибок показал: 1. CoT страдает от "галлюцинаций": модель уверенно рассуждает, но основывается на выдуманных фактах. 2. ReAct менее гибок в формулировках: жесткая структура "Мысль-Действие" иногда мешает свободному ходу рассуждений. 3. ReAct зависит от качества поиска: если поисковая выдача неинформативна, модель может запутаться и не суметь переформулировать запрос.
Лучшие результаты показали гибридные подходы, где модель может переключаться между режимами ReAct и CoT, а также использовать технику Self-Consistency (голосование между несколькими цепочками рассуждений).
На задачах принятия решений (текстовая игра ALFWorld и среда онлайн-покупок WebShop) ReAct уверенно обошел Act-only. Без этапа рассуждения модель не могла разбить сложную цель на понятные шаги.
Источник изображения: Yao и др., 2022
Вывод: ReAct - мощный инструмент, но не серебряная пуля. Его сила раскрывается там, где нужны актуальные данные извне и последовательное планирование.
Практическое применение: используем ReAct в LangChain¶
К счастью, чтобы опробовать ReAct, не нужно писать сложные промпты с нуля. Библиотека LangChain предоставляет готовых "агентов", которые реализуют эту логику. Агент - это цепочка, которая использует LLM для определения последовательности действий с инструментами (поиск, калькулятор, база данных).
Вот пример настройки такого агента с использованием OpenAI и поиска через Serper API.
Сначала установим и импортируем нужные библиотеки:
%%capture
# update or install the necessary libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# import libraries
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# load API keys; you will need to obtain these if you haven't yet
import os
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Теперь создадим LLM, загрузим инструменты (поиск и калькулятор) и инициализируем агента с стратегией zero-shot-react-description. Это как раз и есть реализация ReAct в LangChain.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Запустим агента со сложным запросом, который требует и поиска фактов, и вычислений:
Мы увидим пошаговый процесс работы агента в консоли:
> Entering new AgentExecutor chain...
I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis - see their relationship timeline.
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
Thought: I need to calculate 29 raised to the 0.23 power.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: I now know the final answer.
Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.
> Finished chain.
Ответ модели:
"Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557."
Как это применить в российском контексте? Вместо OpenAI и Serper можно использовать доступные в РФ модели, например, YandexGPT или GigaChat, если для них есть или появятся аналогичные интеграции в LangChain или другие фреймворки. Суть останется той же: модель будет планировать запросы к нужным API (например, к поиску Яндекса или к внутренней базе знаний компании) и обрабатывать результаты.
ReAct - это шаг к созданию по-настоящему разумных агентов, которые не просто повторяют заученное, а умеют ориентироваться в мире информации. Начните с простых экспериментов в LangChain, чтобы почувствовать, как рассуждение и действие дополняют друг друга в работе нейросетей.
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно