Промпт-инжиниринг / Техники промптинга
Мультимодальный промптинг с цепочкой мыслей для анализа текста и изображений¶
Что делать, если нейросети нужно задать вопрос не только по тексту, но и по картинке, схеме или графику? Просто скормить ей изображение недостаточно - для сложных задач требуется, чтобы модель рассуждала, связывая визуальную и текстовую информацию. Именно эту проблему решает техника мультимодальной цепочки мыслей (Multimodal Chain-of-Thought). Это эволюция классического CoT, адаптированная для мира, где данные не ограничиваются словами.
Что такое мультимодальная цепочка мыслей (Multimodal CoT)?¶
Если обычная "цепочка мыслей" учит языковую модель шаг за шагом расписывать свои текстовые рассуждения, то мультимодальный CoT заставляет ее делать то же самое, но с опорой на несколько типов данных - обычно текст и изображение. Ключевая идея, предложенная в работе Zhang и др. (2023), - разделить процесс на две четкие фазы.
Сначала модель генерирует обоснование (rationale), анализируя совместно и картинку, и текстовый контекст вопроса. Она буквально "проговаривает" вслух, что видит и как это связано с вопросом. Затем, на втором шаге, на основе этого детального обоснования она дает окончательный ответ. Такой двухэтапный подход резко повышает прозрачность и точность, особенно в задачах, требующих интерпретации визуальных данных: ответы на вопросы по научным диаграммам, анализ скриншотов интерфейсов, описание графиков.
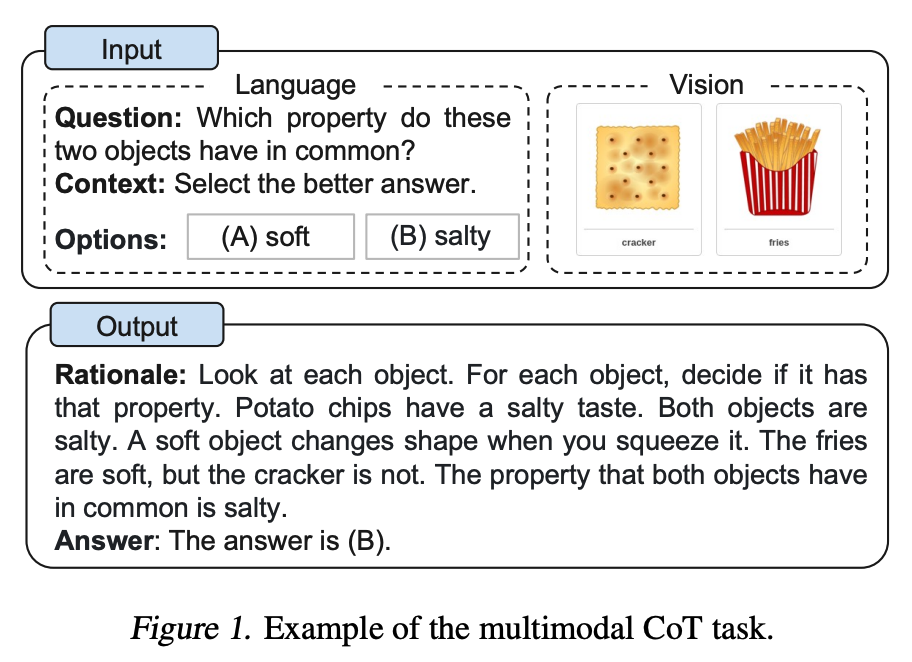
Источник изображения: Zhang и др. (2023)
Как это работает на практике?¶
Представьте, что вы спрашиваете у модели по фотографии товара: "Почему эта ручка может не подойти левше?" Обычный запрос может дать поверхностный ответ. Мультимодальный CoT заставит модель сначала описать конструкцию ручки (расположение клипа, форму grip-зоны), ссылаясь на конкретные элементы изображения, и только потом сделать вывод о удобстве для левшей.
Вот как выглядит структура промпта для модели, поддерживающей мультимодальный ввод (например, GPT-4 Vision или отечественный GigaChat Multimodal):
Промпт:
Вопрос: На изображении показан график. В каком году потребление энергии солнечными панелями впервые превысило 2 квадриллиона БТЕ?
Изображение: [загружается график]
Давай решим по шагам. Сначала опиши, что ты видишь на графике: оси, кривые, подписи. Затем используй это описание, чтобы найти ответ.
Ответ модели (примерный):
Шаг 1 (Анализ изображения): На графике по вертикальной оси отложено "Потребление энергии (квадриллионы БТЕ)", по горизонтальной - годы с 2000 по 2020. Я вижу две кривые: одна подписана "Гидроэнергия", она почти плоская. Вторая - "Солнечная энергия", она начинается близко к нулю около 2000 года и резко растет после 2010. Возле кривой солнечной энергии есть точки с значениями. Нужно найти точку, где эта кривая пересекает отметку в 2 квадриллиона БТЕ.
Шаг 2 (Ответ): Глядя на график, кривая солнечной энергии достигает значения 2 квадриллиона БТЕ примерно между 2015 и 2016 годом. Более точно, это происходит в 2016 году.
Почему это эффективно? Сравнение с обычными методами¶
Исследования показывают, что даже относительно небольшие модели, специально обученные с мультимодальным CoT (например, на 1 млрд параметров), могут превосходить гигантов вроде GPT-3.5 на специализированных бенчмарках, таких как ScienceQA. Причина - в фокусе на рассуждении. Модель не пытается угадать ответ сходу, а строит его на фундаменте детального, многошагового анализа. Это снижает количество "галлюцинаций" и ошибок, вызванных невнимательным просмотром изображения.
Для бизнеса в РФ это открывает возможности в автоматизации анализа отчетов с графиками (например, в финансовых или маркетинговых службах), проверки соответствия товаров на фото их описанию, или обучения ИИ-ассистентов понимать скриншоты из корпоративных систем (1С, CRM). Технику можно применять в доступных из России мультимодальных моделях, таких как YandexGPT или GigaChat, правильно структурируя промпты.
Как внедрить эту технику?¶
- Выберите модель. Нужна модель, принимающая на вход и текст, и изображение (мультимодальная).
- Сконструируйте двухэтапный промпт. Четко разделите инструкцию на этап "рассуждения/описания" и этап "ответа". Используйте директивы: "Сначала опиши, что на изображении...", "Основываясь на этом описании, ответь...".
- Давайте контекст. В текстовой части промпта укажите, что именно нужно искать на изображении.
- Тестируйте и уточняйте. Первые ответы могут быть неполными. Уточняйте промпт, прося быть более детальным в описании или связывать конкретные элементы изображения с вопросом.
Эта техника - мощный инструмент в арсенале промпт-инжиниринга, стирающий границы между текстом и визуалом. Она приближает нас к созданию ИИ-ассистентов, которые понимают мир так же многогранно, как человек.
Дополнительная литература: - Language Is Not All You Need: Aligning Perception with Language Models (Feb 2023)
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно