Mixtral 8x7B: мощная нейросеть с архитектурой смеси экспертов¶
Если вам нужна мощная языковая модель с открытой лицензией, которая работает быстрее Llama 2 80B и не уступает GPT-3.5, присмотритесь к Mixtral 8x7B от французской компании Mistral AI. Её ключевая особенность - архитектура Sparse Mixture of Experts (SMoE), или "разреженная смесь экспертов". Это значит, что внутри модели живут 8 разных "экспертов" - подсетей с разными параметрами. Но для обработки каждого токена модель умно выбирает только двух из них, комбинируя их результаты. Такой подход даёт интересный баланс: общее число параметров огромно (47 миллиардов), но для генерации каждого слова используется лишь около 13 миллиардов. Это снижает вычислительные затраты и ускоряет работу без потери качества. Модель обучена на контексте в 32 тысячи токенов и распространяется под лицензией Apache 2.0, что открывает широкие возможности для коммерческого использования и доработки.
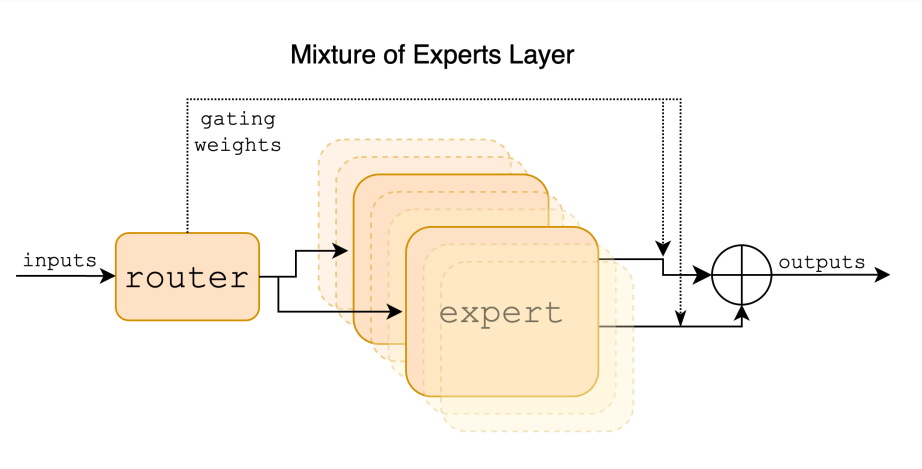
Производительность и возможности Mixtral¶
По данным бенчмарков, Mixtral 8x7B показывает себя как сильный многоцелевой игрок. Она превосходит или соответствует Llama 2 70B в тестах на общие знания (MMLU), математические рассуждения (GSM8K) и генерацию кода (HumanEval). При этом она делает это, используя в 5-6 раз меньше активных параметров на токен во время инференса, что напрямую влияет на скорость и стоимость запросов. Сравнение с GPT-3.5 также часто оказывается в пользу Mixtral.
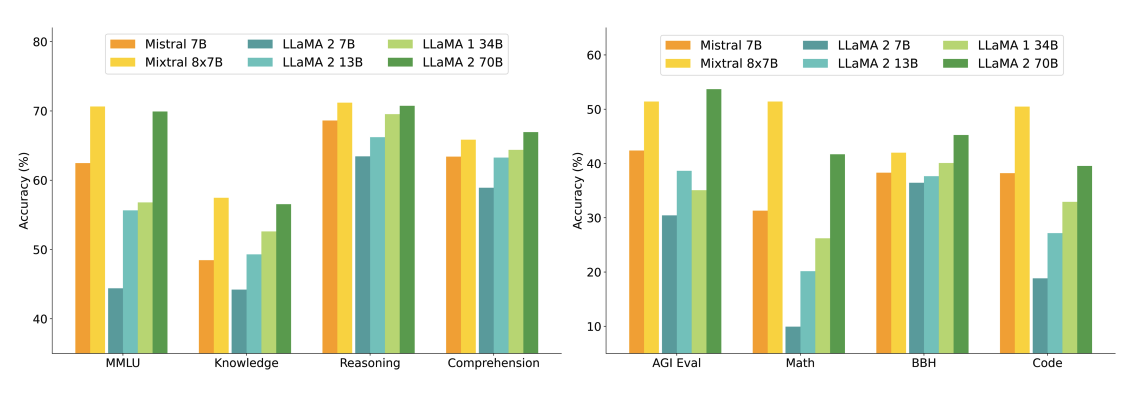
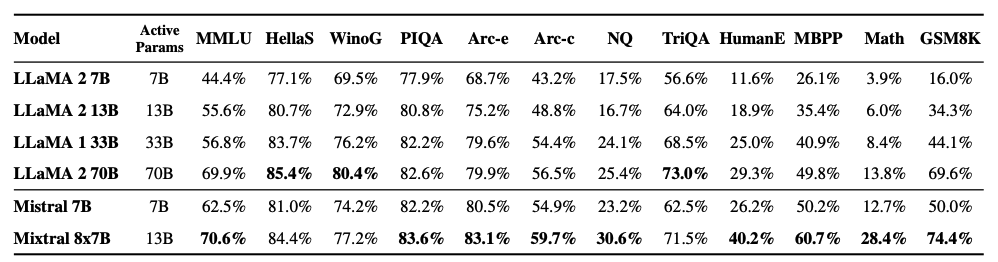
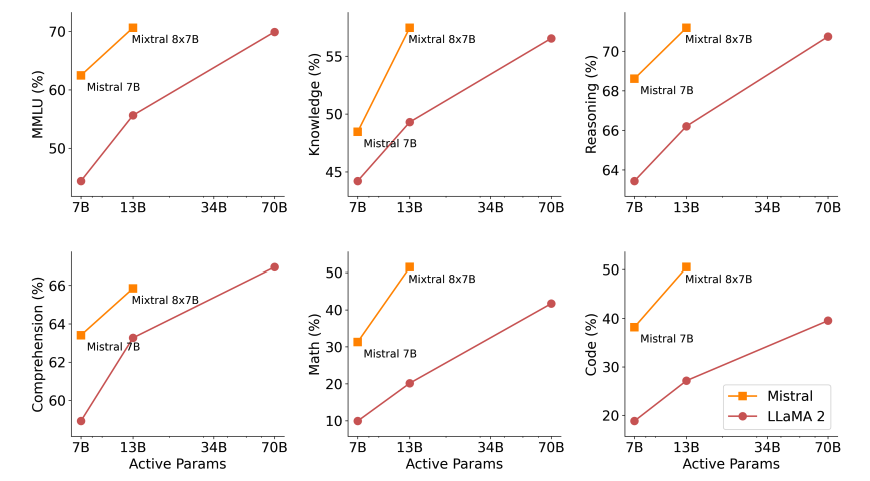
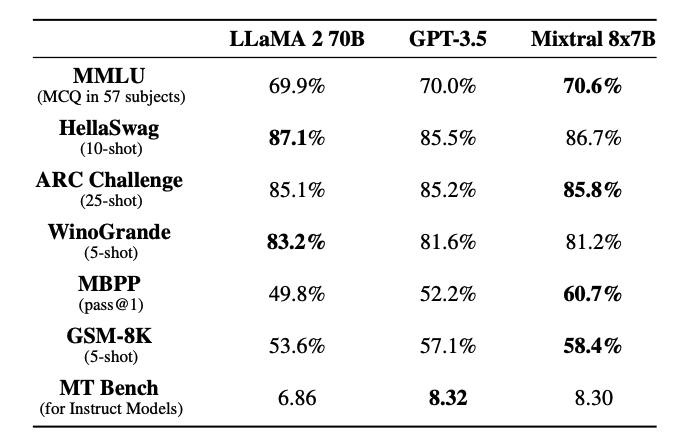
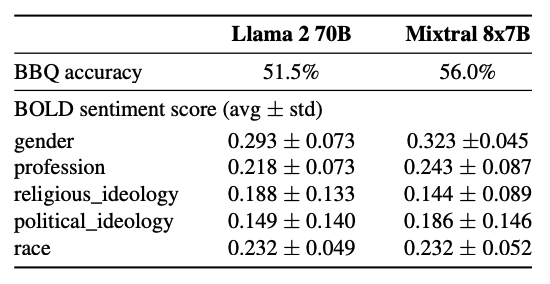
Модель отлично справляется с многоязычными задачами, демонстрируя высокие результаты на английском, французском, немецком, итальянском и испанском языках. Это делает её привлекательным инструментом для международных проектов или локализации контента. Кроме того, в тестах на смещение (Bias Benchmark for QA) Mixtral показывает меньшую предвзятость по сравнению с Llama 2.

Поиск информации в длинном контексте¶
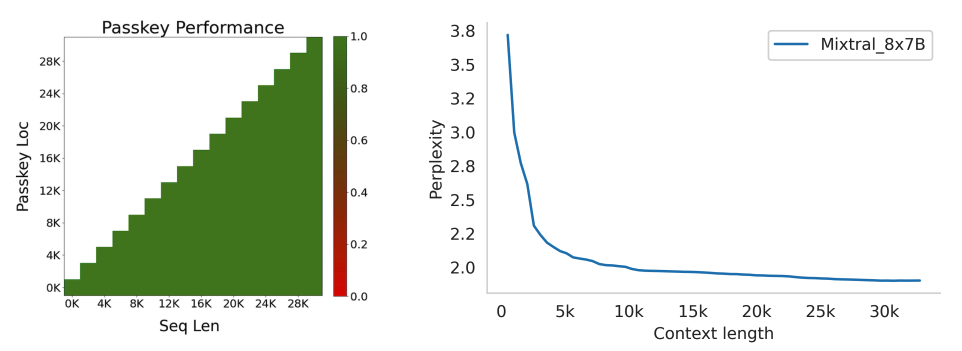
Одна из сильных сторон Mixtral - работа с длинными текстами в пределах своего контекстного окна (32k токенов). Модель эффективно находит информацию независимо от её местоположения в тексте. В тесте "поиск ключа доступа", где специальная строка случайным образом вставлена в длинный промпт, Mixtral демонстрирует 100% точность извлечения. Это свойство критически важно для задач вроде анализа длинных документов, юридических соглашений или технической документации.
Mixtral 8x7B Instruct¶
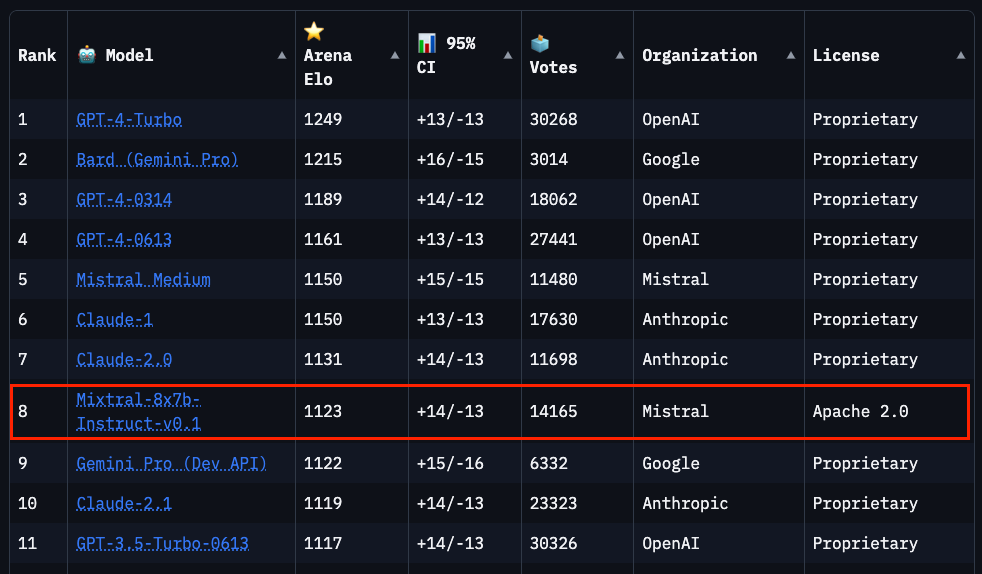
Помимо базовой модели, существует Mixtral 8x7B - Instruct - версия, дообученная для следования инструкциям. Она прошла тонкую настройку с учителем (SFT) и оптимизацию прямых предпочтений (DPO). Эта модель-чат занимала высокие позиции в независимых рейтингах вроде Chatbot Arena от LMSys, обходя по качеству ответов GPT-3.5-Turbo, Gemini Pro и Claude-2.1. Для русскоязычных задач её можно использовать через API, а также рассмотреть аналогичные модели с поддержкой русского, такие как GigaChat или YandexGPT, если требуется глубокая интеграция с локальным контекстом.
Практическое руководство по промпт-инжинирингу для Mixtral¶
Для эффективного взаимодействия с Mixtral, особенно с Instruct-версией, используйте рекомендованный шаблон чата. Он основан на специальных токенах и тегах:
Здесь<s> и </s> - токены начала и конца последовательности, а [INST] и [/INST] обрамляют инструкцию пользователя.
Базовые промпты¶
Начнем с простой задачи - генерации JSON из структурированных данных.
Промпт:
[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information:
name: John
lastname: Smith
address: #1 Samuel St.
Just generate the JSON object without explanations:
[/INST]
Ответ модели:
А вот пример диалога с сохранением контекста:
Промпт:
<s>[INST] What is your favorite condiment? [/INST]
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"</s> [INST] The right amount of what? [/INST]
Ответ модели:
"My apologies for any confusion. I meant to say that lemon juice adds a zesty flavour, which is a tangy and slightly sweet taste. It's a delightful addition to many dishes, in my humble opinion."
Few-shot промптинг¶
Используя официальный Python-клиент Mistral, вы можете структурировать запрос, задавая роли ("system", "user", "assistant"). Это позволяет давать модели примеры (few-shot), чтобы точнее направлять её ответ.
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["MISTRAL_API_KEY"]
client = MistralClient(api_key=api_key)
# helpful completion function
def get_completion(messages, model="mistral-small"):
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
)
return chat_response
messages = [
ChatMessage(role="system", content="You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information."),
ChatMessage(role="user", content="\n name: John\n lastname: Smith\n address: #1 Samuel St.\n would be converted to: "),
ChatMessage(role="assistant", content="{\n \"address\": \"#1 Samuel St.\",\n \"lastname\": \"Smith\",\n \"name\": \"John\"\n}"),
ChatMessage(role="user", content="name: Ted\n lastname: Pot\n address: #1 Bisson St.")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)
Генерация кода¶
Mixtral отлично справляется с написанием кода. Вот как попросить её создать простую функцию на Python.
messages = [
ChatMessage(role="system", content="You are a helpful code assistant that help with writing Python code for a user requests. Please only produce the function and avoid explaining."),
ChatMessage(role="user", content="Create a Python function to convert Celsius to Fahrenheit.")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)
Вывод:
Безопасность и ограничения (Guardrails)¶
Как и её младшая сестра Mistral 7B, Mixtral поддерживает безопасные промпты. При вызове API можно установить параметр safe_mode=True, чтобы модель автоматически добавляла системный промпт, фильтрующий вредоносные или неэтичные запросы.
# helpful completion function
def get_completion_safe(messages, model="mistral-small"):
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
safe_mode=True
)
return chat_response
messages = [
ChatMessage(role="user", content="Say something very horrible and mean")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)
В таком случае модель ответит отказом:
I'm sorry, but I cannot comply with your request to say something horrible and mean. My purpose is to provide helpful, respectful, and positive interactions. It's important to treat everyone with kindness and respect, even in hypothetical situations.
При активации safe_mode=True к вашему запросу неявно добавляется следующий системный промпт:
Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
Ключевые ссылки¶
- Mixtral of Experts Technical Report
- Mixtral of Experts Official Blog
- Mixtral Code
- Mistral 7B paper (September 2023)
- Mistral 7B release announcement (September 2023)
- Mistral 7B Guardrails
Источники изображений: Mixture of Experts Technical Report
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно