LLaMA: революция в мире языковых моделей от Meta¶
Когда речь заходит о больших языковых моделях, кажется логичным, что чем больше параметров, тем умнее модель. Но команда исследователей из Meta в 2023 году бросила вызов этому стереотипу, представив семейство моделей LLaMA. Их ключевая идея проста и элегантна: при ограниченных вычислительных ресурсах лучше обучать компактную модель на гигантском объеме данных, чем гнаться за сотнями миллиардов параметров. Этот подход не просто теоретический - он привел к созданию моделей, которые обходят монстров вроде GPT-3, будучи в разы меньше и доступнее.
Что такое LLaMA и почему это важно?¶
LLaMA (Large Language Model Meta AI) - это не одна модель, а целое семейство, представленное в размерах 7B, 13B, 33B и 65B параметров. Цифра в названии указывает на миллиарды параметров. Самое удивительное в них - не размер, а стратегия обучения. Исследователи Meta взяли за основу работу Hoffman et al., 2022, которая показала, что модель на 10 миллиардов параметров, обученная на 200 миллиардах токенов (фрагментов текста), может быть очень эффективной. Однако они пошли дальше и обнаружили, что даже 7-миллиардная модель продолжает улучшать свои показатели, когда объем данных для обучения переваливает за триллион токенов.
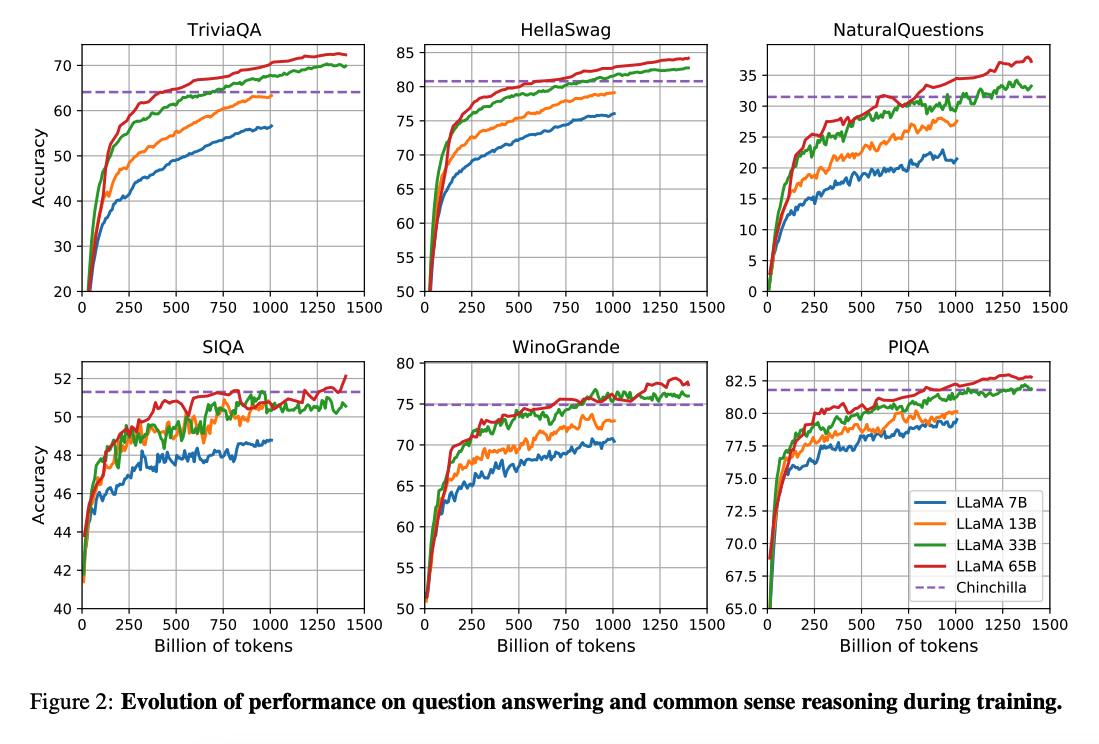
На практике это означает, что LLaMA-13B, будучи в 10 раз меньше GPT-3 (175B), показывает лучшие результаты на множестве тестовых benchmarks. А флагманская LLaMA-65B успешно конкурирует с такими титанами, как Chinchilla-70B и даже PaLM-540B. Для бизнеса и разработчиков в России и СНГ это открывает уникальные возможности: мощные модели, которые можно запустить на одном GPU, а не на кластере серверов. Это снижает порог входа для разработки собственных AI-решений, будь то чат-боты для поддержки клиентов, аналитика текстов или генерация контента.
Ключевые возможности и практическое применение¶
Главный прорыв LLaMA - в ее открытости и эффективности. После первоначального релиза модель стала фундаментом для десятков производных проектов с открытым исходным кодом. Это напрямую повлияло на экосистему: благодаря относительно небольшому размеру, модели LLaMA стало возможно дообучать (fine-tune) под конкретные задачи с умеренными вычислительными затратами.
- Конкурентность с закрытыми гигантами: Как уже упоминалось, LLaMA-13B превосходит GPT-3 по многим параметрам. Это дает альтернативу, не зависящую от API зарубежных компаний.
- Работа на одном GPU: Модели размером до 13B параметров могут работать на потребительских видеокартах высокого класса (например, NVIDIA RTX 4090) или на облачных инстансах с одним GPU. Это делает эксперименты и развертывание значительно дешевле.
- Фундамент для инноваций: Исходный код и архитектура LLaMA стали основой для множества специализированных моделей. Например, на ее базе созданы медицинский чат-бот ChatDoctor, диалоговые модели Koala и Vicuna, а также известный проект Stanford Alpaca.
Для русскоязычных разработчиков это особенно актуально. Можно взять базовую LLaMA и дообучить ее на корпусах русских текстов для улучшения понимания контекста и грамматики, создавая тем самым более качественные локальные аналоги зарубежных сервисов. Альтернативой может служить использование доступных в РФ моделей, таких как YandexGPT или GigaChat, для решения бизнес-задач, где важна интеграция с локальными сервисами и глубокое понимание русского языка.
Примеры проектов на базе LLaMA¶
После выхода оригинальной работы сообщество быстро оценило потенциал LLaMA. Вот некоторые из ключевых проектов, которые ее используют:
- Stanford Alpaca (Март 2023): Модель, инструктивно дообученная на основе LLaMA 7B для следования командам человека.
- Vicuna (Март 2023): Открытый чат-бот, дообученный на пользовательских диалогах с ChatGPT. Разработчики заявляют, что он достигает 90% качества ChatGPT.
- Koala (Апрель 2023): Диалоговая модель для академических исследований, обученная на данных из публичных источников.
- ChatDoctor (Март 2023): Медицинская чат-модель, дообученная на знаниях из медицинской области.
- LLaMA-Adapter (Март 2023): Метод эффективной тонкой настройки языковых моделей с помощью "адаптеров", требующий всего час обучения для адаптации LLaMA к новым задачам.
- Baize (Апрель 2023): Открытая чат-модель, использующая эффективную настройку на данных само-диалогов.
- GPT4All (Март 2023): Экосистема для обучения и развертывания мощных и персонализированных языковых моделей, работающих на потребительском железе.
Заключение¶
LLaMA от Meta совершила переворот, доказав, что эффективность и масштабируемость важнее грубой силы. Она демократизировала доступ к передовым технологиям ИИ, позволив небольшим командам и энтузиастам работать с моделями, конкурирующими с продуктами гигантов индустрии. Для бизнеса это означает снижение затрат на внедрение AI, возможность кастомизации под свои нужды и меньшую зависимость от внешних API. Для разработчиков в русскоязычном сегменте LLaMA и ее производные - это мощный инструмент для создания инновационных решений, адаптированных к локальным требованиям и языковым особенностям.
Оригинальная статья: LLaMA: Open and Efficient Foundation Language Models Официальный репозиторий кода: https://github.com/facebookresearch/llama
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно