Обучение на инструкциях: как масштабировать языковые модели¶
Когда большая языковая модель уже натренирована на гигантских массивах текста, возникает вопрос: как заставить ее не просто генерировать текст, а точно следовать указаниям человека и решать конкретные задачи? Ответ - метод дообучения на инструкциях (instruction tuning). Это не просто тонкая настройка, а целенаправленное обучение модели понимать и выполнять тысячи разнообразных задач, сформулированных как команды. Исследования, в частности от команды Google, показывают, что грамотное масштабирование этого процесса - по количеству задач и размеру модели - кардинально улучшает качество работы AI.
Суть метода: обучение тысячью задачами¶
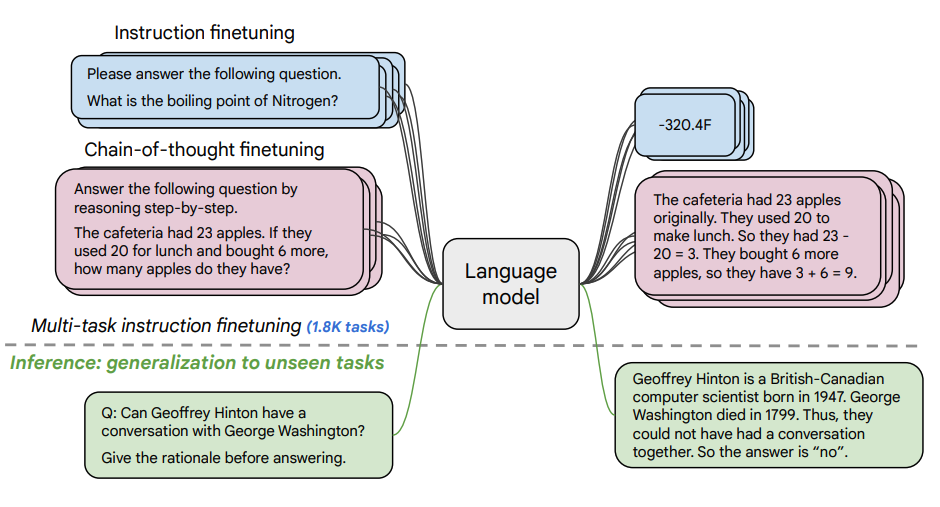
Источник изображения: Scaling Instruction-Finetuned Language Models
Ключевая идея проста: чтобы модель научилась следовать инструкциям, ее нужно натаскать на огромном количестве примеров. В исследовании для этого использовали 1.8 тысячи различных задач, переформулированных в виде четких указаний. Модель дообучили на этом миксе, включающем задачи с примерами (few-shot) и без (zero-shot), а также задачи, требующие пошаговых рассуждений (chain-of-thought, CoT).
Представьте, что вы учите универсального помощника: вы даете ему не один тип поручений («напиши письмо»), а тысячи - от перевода текста и классификации отзывов до решения логических головоломок и генерации кода. Так модель учится обобщать сам принцип следования инструкции, а не просто запоминать ответы на конкретные вопросы.
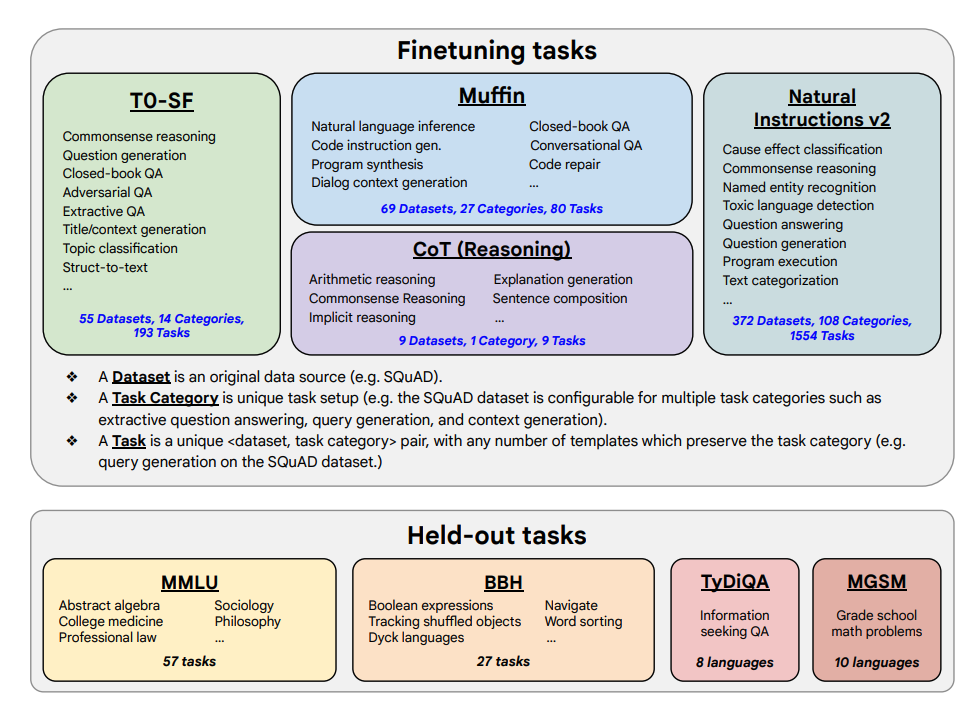
Ключевые выводы: что дает масштабирование?¶
Практические эксперименты с моделями PaLM и T5 (в версии Flan) выявили несколько важных закономерностей, полезных для любого, кто работает с большими моделями.
- Масштабирование работает. Производительность модели стабильно растет с увеличением как количества задач для дообучения, так и размера самой модели (числа параметров). Это указывает на то, что путь к более умным AI лежит через дальнейшее увеличение и того, и другого, хотя отдача от добавления новых задач со временем снижается.
- Цепочка мыслей - ключ к рассуждениям. Включение в обучающий набор данных с пошаговыми рассуждениями (CoT) радикально улучшает способность модели решать задачи, требующие логики, арифметики или здравого смысла. Лучший результат дает совместное обучение на обычных инструкциях и инструкциях с CoT.
- Универсальность и контроль. Модели, прошедшие такое обучение (например, Flan-PaLM), не только лучше справляются с тестами (MMLU, TyDiQA), но и становятся более управляемыми: они реже игнорируют инструкции, меньше «галлюцинируют» и генерируют более уместные открытые ответы. Также улучшаются их мультиязычные способности.
- Эффект самосогласованности. Использование техники самосогласованности (генерация нескольких цепочек рассуждений и выбор наиболее частого ответа) в сочетании с CoT-обучением дает скачок качества в математических и логических задачах.
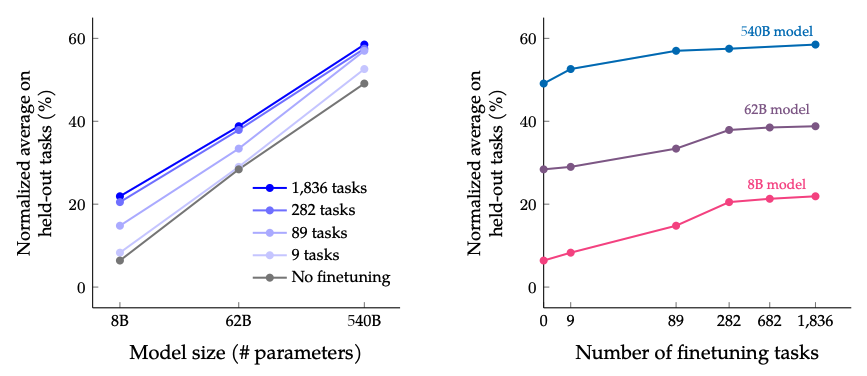
Источник изображения: Scaling Instruction-Finetuned Language Models
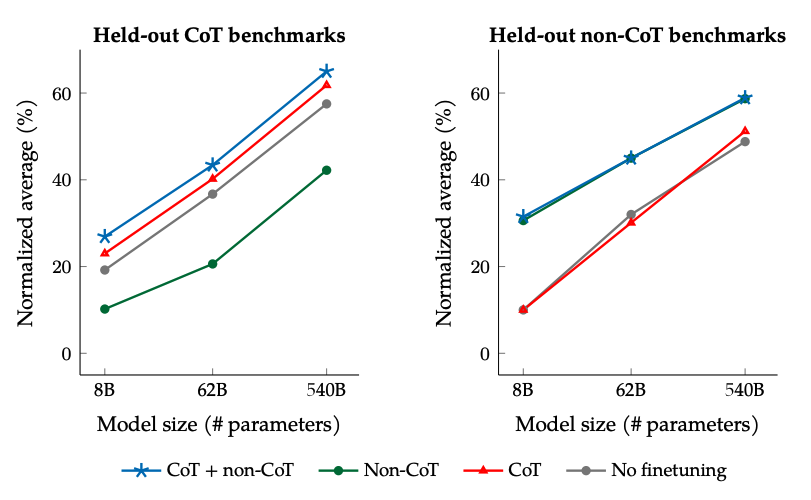
Источник изображения: Scaling Instruction-Finetuned Language Models
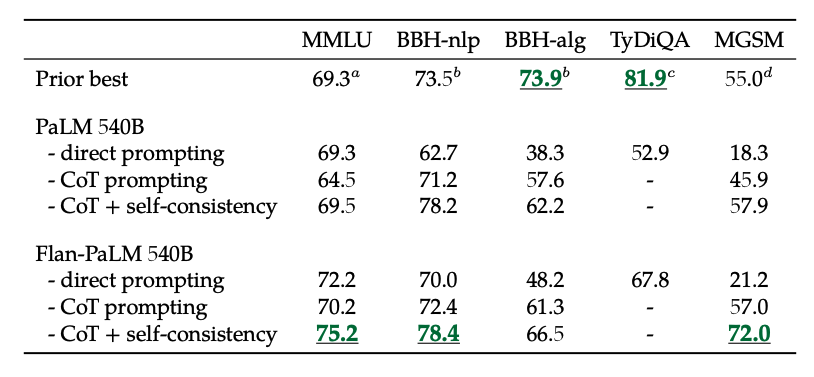
Источник изображения: Scaling Instruction-Finetuned Language Models
Практический результат: Flan-PaLM против обычной PaLM¶
Нагляднее всего преимущества видны в сравнении. Обычная большая модель PaLM в режиме zero-shot (без примеров) может давать сбои: повторять вопрос, уходить в бессмысленные повторы или просто отказываться выполнять инструкцию.
Промпт:
Объясни, почему следующий анекдот смешной.
Анекдот: Вчера видел парня, который потерял левую руку. Ну думаю, теперь ему будет не до чего.
Парень потерял левую руку. Теперь ему будет не до чего. Парень потерял левую руку. Теперь ему будет не до чего. Парень потерял...
Flan-PaLM, дообученная на инструкциях, таких проблем избегает. Она адекватно анализирует запрос и дает осмысленный ответ, потому что понимает саму суть задачи «объясни, почему».
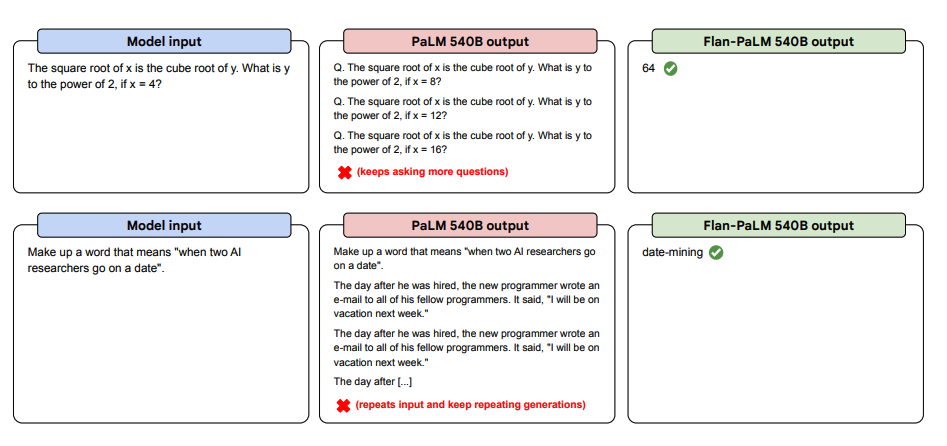
Источник изображения: Scaling Instruction-Finetuned Language Models
Более того, Flan-PaLM демонстрирует впечатляющие результаты в zero-shot режиме на сложных, незнакомых задачах, требующих генерации развернутого ответа: от анализа моральных дилемм до планирования мероприятий.
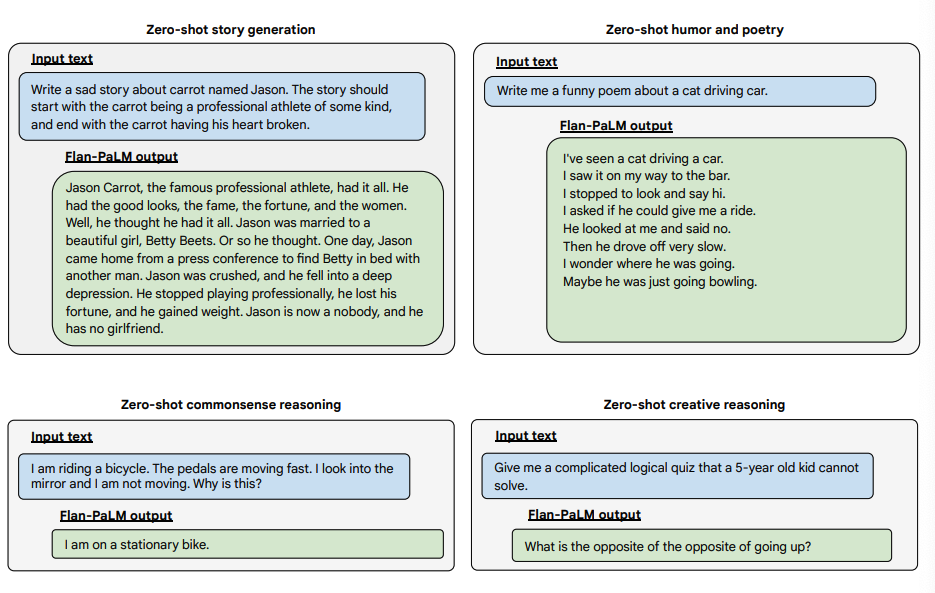
Источник изображения: Scaling Instruction-Finetuned Language Models
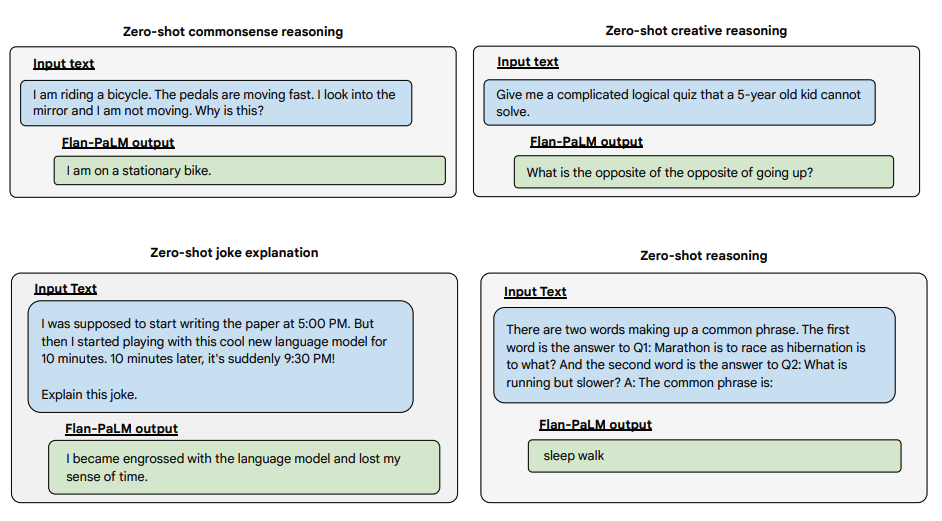
Источник изображения: Scaling Instruction-Finetuned Language Models
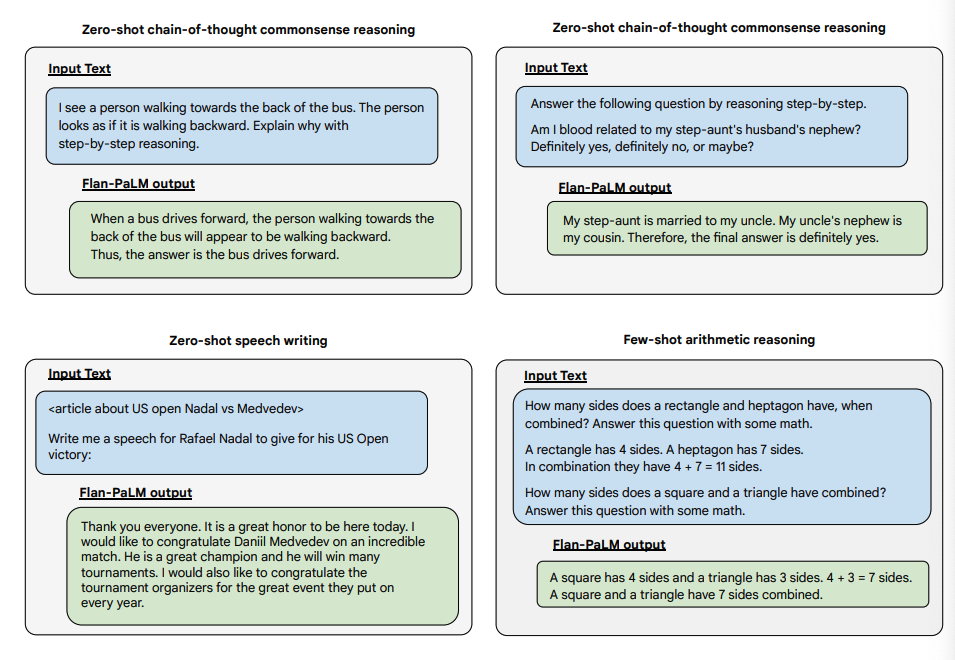
Источник изображения: Scaling Instruction-Finetuned Language Models
Важно, что этот подход работает и для моделей поменьше. Flan-T5 (дообученная версия T5) с значительно меньшим числом параметров показывает результаты, сопоставимые или превосходящие оригинальные большие модели на многих тестах, что делает технологию более доступной. Попробовать Flan-T5 можно, например, на Hugging Face Hub.
Что это значит для практики?¶
Для российских разработчиков и компаний, работающих с AI, эти принципы крайне важны. При дообучении открытых или собственных моделей (таких как GigaChat или YandexGPT, если доступны для тонкой настройки) стоит делать ставку на: 1. Разнообразие задач. Собирать или генерировать максимально разнородный набор инструкций на русском языке, покрывающий все нужные сценарии. 2. Обязательное включение CoT. Добавление в датасет примеров с пошаговыми рассуждениями резко повысит интеллектуальные возможности модели для бизнес-аналитики, решения задач и консультирования. 3. Масштаб. Чем больше качественных данных для instruction tuning и чем крупнее модель (в разумных пределах инфраструктуры), тем лучше будет итоговое качество и управляемость.
Обучение на инструкциях переводит языковые модели из состояния «эрудированного рассказчика» в состояние «исполнительного и рассуждающего помощника», и масштабирование этого процесса - проверенный путь к созданию более полезного и надежного искусственного интеллекта.
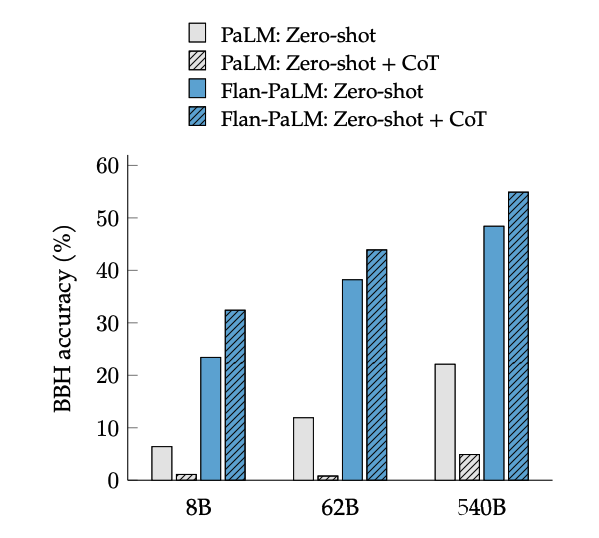
Источник изображения: Scaling Instruction-Finetuned Language Models
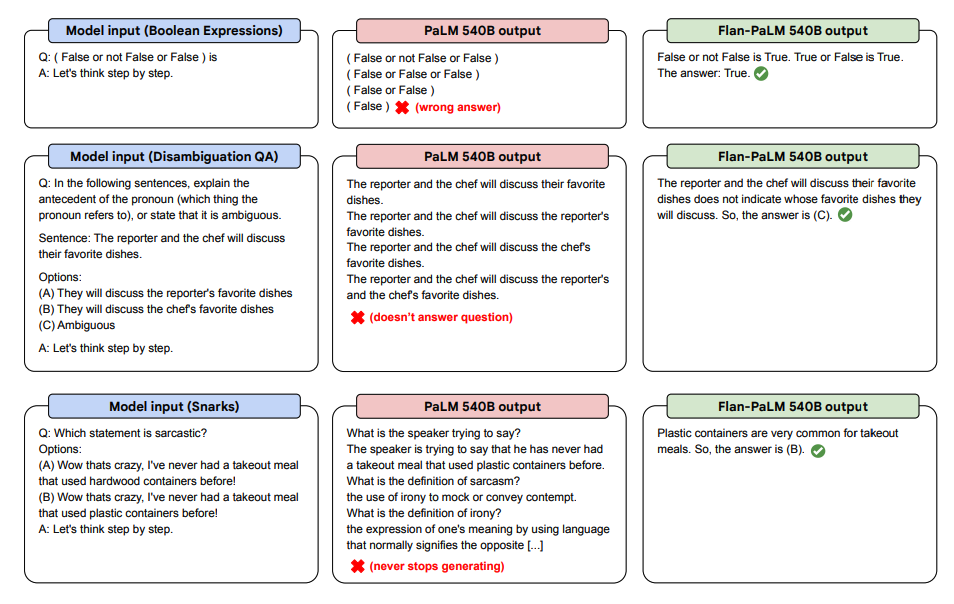
Источник изображения: Scaling Instruction-Finetuned Language Models
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно