Как сделать свою нейросеть с нуля на Python¶
Разбираемся, как построить нейросеть с нуля - без магии фреймворков, только Python и математика. В конце у вас будет рабочая сеть, которая умеет обучаться на данных и делать предсказания. Это фундамент: поняв его, вы будете осознанно работать с TensorFlow и PyTorch, а не просто копировать чужой код.
Что понадобится¶
- Python 3.8+ - бесплатно, скачать с python.org без ограничений из РФ.
- NumPy - бесплатная библиотека, ставится одной командой.
- TensorFlow/Keras или PyTorch - опционально, для шага с фреймворком. Оба бесплатны, скачиваются без VPN. Облачные GPU (Google Colab, AWS) из России оплатить сложно - используйте локальную машину или ищите российские облачные альтернативы.
- Текстовый редактор или Jupyter Notebook.
Никаких платных подписок для базового урока не нужно.
Шаг 1. Установка библиотек¶
Откройте терминал и выполните:
Если хотите сразу попробовать готовый фреймворк:
# TensorFlow/Keras
pip install tensorflow
# PyTorch (для CPU, без GPU)
pip install torch torchvision torchaudio
Для PyTorch с GPU зайдите на pytorch.org, выберите свою ОС и версию CUDA - сайт сгенерирует точную команду.
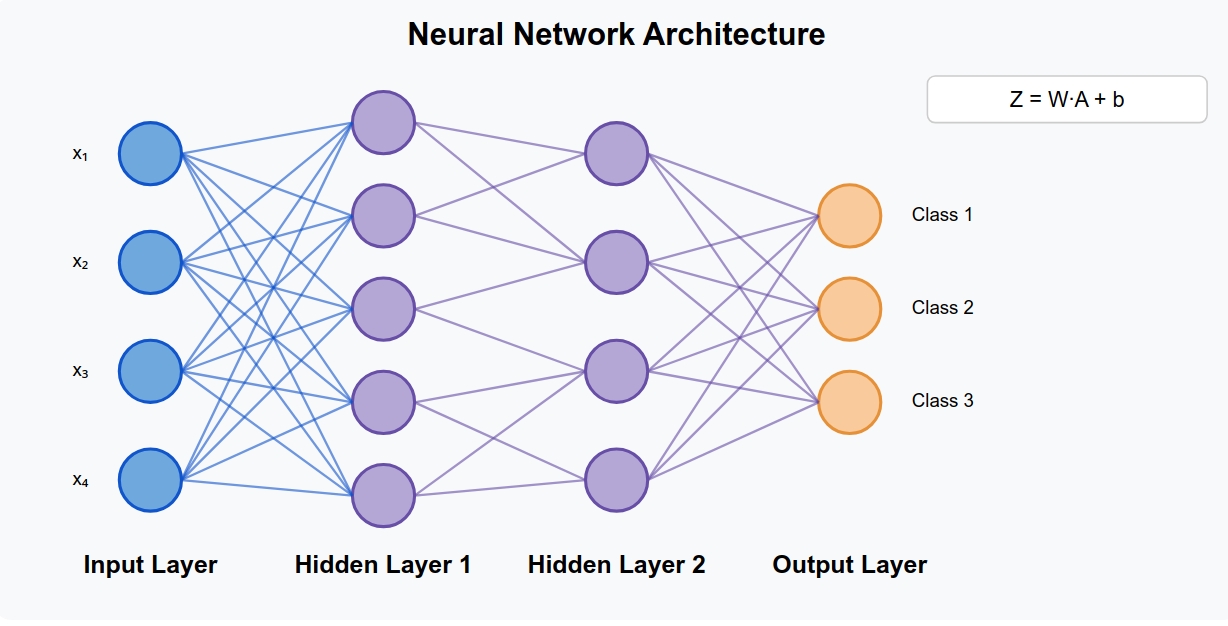
Шаг 2. Определите архитектуру сети¶
 Скриншот: ahammadnafiz.github.io
Скриншот: ahammadnafiz.github.io
Перед кодом ответьте на три вопроса:
- Сколько входных признаков у ваших данных? Например, 2 признака для задачи XOR.
- Сколько скрытых слоев и нейронов в каждом? Начните с одного скрытого слоя из 4 нейронов.
- Сколько выходных нейронов? Для бинарной классификации - 1, для многоклассовой - по числу классов.
Функции активации: для скрытых слоев берите ReLU, для выходного - Sigmoid (бинарная задача) или Softmax (несколько классов). Sigmoid и Tanh в глубоких сетях вызывают затухание градиентов - это известная проблема, ReLU её решает.
Шаг 3. Инициализируйте веса¶
Создайте файл neural_net.py и добавьте:
import numpy as np
def initialize_parameters(layer_dims):
params = {}
for l in range(1, len(layer_dims)):
# He initialization для ReLU
params[f'W{l}'] = np.random.randn(layer_dims[l], layer_dims[l-1]) * np.sqrt(2. / layer_dims[l-1])
params[f'b{l}'] = np.zeros((layer_dims[l], 1))
return params
# Пример: 2 входа, 4 нейрона в скрытом слое, 1 выход
layer_dims = [2, 4, 1]
params = initialize_parameters(layer_dims)
Нули для весов не подходят - все нейроны будут обучаться одинаково. He initialization специально подобрана под ReLU и предотвращает взрывающиеся градиенты.
Шаг 4. Реализуйте прямое распространение¶
def relu(Z):
return np.maximum(0, Z)
def sigmoid(Z):
return 1 / (1 + np.exp(-Z))
def forward_pass(X, params, num_layers):
cache = {'A0': X}
A = X
for l in range(1, num_layers):
Z = np.dot(params[f'W{l}'], A) + params[f'b{l}']
A = relu(Z)
cache[f'Z{l}'] = Z
cache[f'A{l}'] = A
# Выходной слой
Z_out = np.dot(params[f'W{num_layers}'], A) + params[f'b{num_layers}']
AL = sigmoid(Z_out)
cache[f'Z{num_layers}'] = Z_out
cache[f'A{num_layers}'] = AL
return AL, cache
Сохраняйте все промежуточные значения в cache - они понадобятся на обратном проходе.
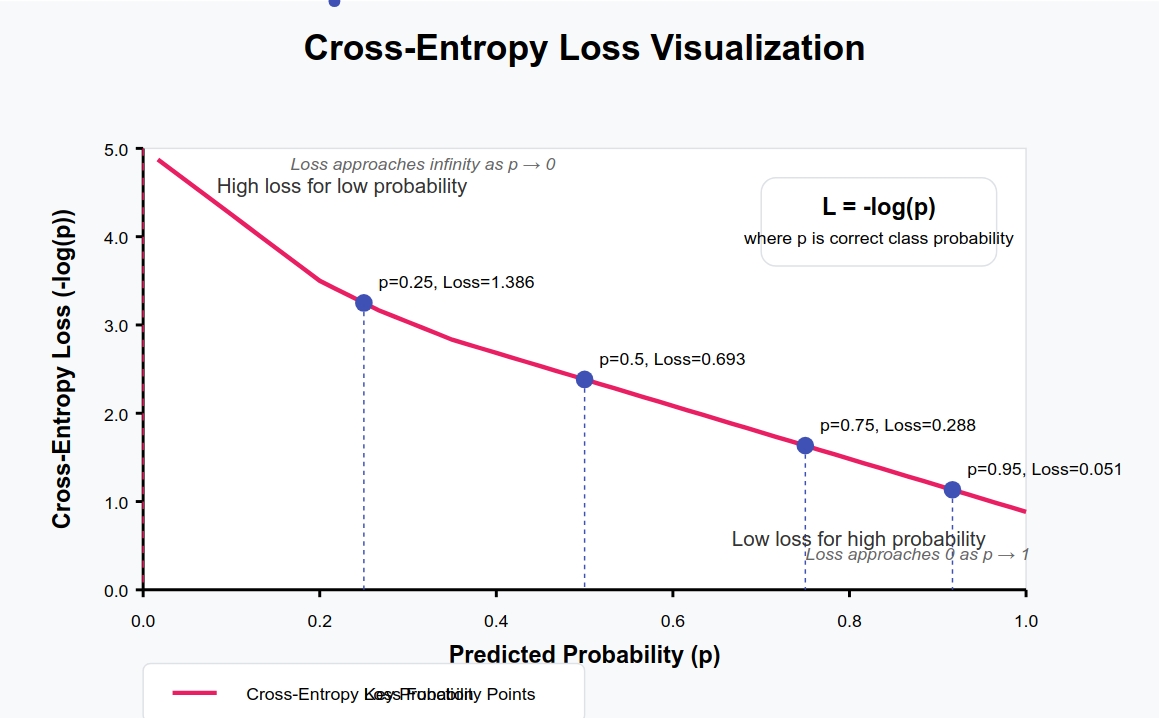
Шаг 5. Вычислите функцию потерь¶
 Скриншот: ahammadnafiz.github.io
Скриншот: ahammadnafiz.github.io
def compute_loss(AL, Y):
epsilon = 1e-8 # защита от log(0)
loss = -np.mean(Y * np.log(AL + epsilon) + (1 - Y) * np.log(1 - AL + epsilon))
return loss
epsilon - маленькое число, которое спасает от NaN при логарифме нуля. Без него сеть сломается на первой же эпохе.
Шаг 6. Обратное распространение¶
Это самый сложный шаг. Двигаемся от выходного слоя к входному и считаем градиенты:
def backward_pass(AL, Y, cache, params, num_layers):
grads = {}
m = Y.shape[1]
# Градиент выходного слоя (Sigmoid + бинарная кросс-энтропия)
dA = -(Y / (AL + 1e-8) - (1 - Y) / (1 - AL + 1e-8))
for l in reversed(range(1, num_layers + 1)):
Z = cache[f'Z{l}']
A_prev = cache[f'A{l-1}']
if l == num_layers:
dZ = dA * AL * (1 - AL) # производная Sigmoid
else:
dZ = dA * (Z > 0) # производная ReLU
grads[f'dW{l}'] = np.dot(dZ, A_prev.T) / m
grads[f'db{l}'] = np.mean(dZ, axis=1, keepdims=True)
dA = np.dot(params[f'W{l}'].T, dZ)
return grads
Подробнее о том, как устроены градиенты и почему это работает, читайте в гайде по промпт-инжинирингу - там же разбираем, как интуиция за математикой помогает лучше формулировать задачи для моделей.
Шаг 7. Обновите параметры¶
def update_parameters(params, grads, learning_rate, num_layers):
for l in range(1, num_layers + 1):
params[f'W{l}'] -= learning_rate * grads[f'dW{l}']
params[f'b{l}'] -= learning_rate * grads[f'db{l}']
return params
learning_rate обычно берут от 0.001 до 0.1. Начните с 0.01 и смотрите на потери.
Шаг 8. Цикл обучения¶
def train(X, Y, layer_dims, epochs=1000, learning_rate=0.01):
num_layers = len(layer_dims) - 1
params = initialize_parameters(layer_dims)
for epoch in range(epochs):
AL, cache = forward_pass(X, params, num_layers)
loss = compute_loss(AL, Y)
grads = backward_pass(AL, Y, cache, params, num_layers)
params = update_parameters(params, grads, learning_rate, num_layers)
if epoch % 100 == 0:
print(f'Epoch {epoch}, Loss: {loss:.4f}')
return params
Потери должны монотонно убывать. Если они растут или прыгают - скорее всего, слишком высокий learning_rate.
Шаг 9. Предсказание¶
def predict(X, params, num_layers):
AL, _ = forward_pass(X, params, num_layers)
return (AL > 0.5).astype(int) # порог 0.5 для бинарной классификации
Запустите всё вместе на задаче XOR:
X = np.array([[0,0,1,1],[0,1,0,1]])
Y = np.array([[0,1,1,0]])
trained_params = train(X, Y, [2, 4, 1], epochs=5000, learning_rate=0.1)
print(predict(X, trained_params, 2))
Если всё сделано правильно, получите [[0 1 1 0]].
Частые ошибки¶
- Нулевая инициализация весов. Все нейроны обучаются одинаково и сеть не учится. Всегда используйте случайную инициализацию - He для ReLU, Xavier для Sigmoid.
- Слишком большой learning rate. Потери начинают расти или уходят в
NaN. Уменьшите в 10 раз и попробуйте снова. - Забыли epsilon в логарифме.
log(0)дает-inf, и все параметры превращаются вNaNуже на первой эпохе. - Переобучение. Сеть идеально работает на тренировочных данных, но ошибается на новых. Добавьте Dropout или L2-регуляризацию, следите за потерями на валидационной выборке.
Вопросы и ответы¶
Зачем писать нейросеть с нуля, если есть TensorFlow и PyTorch?
Фреймворки скрывают детали реализации. Когда вы напишете backpropagation руками, вы поймете, почему выбор функции активации влияет на скорость обучения, откуда берутся градиенты и что происходит внутри model.fit(). Это знание помогает отлаживать реальные модели и осознанно выбирать архитектуру. Посмотрите каталог LLM-моделей - там видно, насколько разные архитектуры решают разные задачи.
Можно ли обучать такую сеть без GPU в России?
Да, для учебных задач CPU вполне хватает. NumPy-реализация работает на любом ноутбуке. Проблемы начинаются с большими датасетами и глубокими сетями - тогда нужен GPU. Облачные сервисы с GPU (Google Colab, AWS) из России оплатить сложно, поэтому реалистичный вариант - собственная видеокарта NVIDIA или российские облачные платформы.
Когда переходить с NumPy на TensorFlow или PyTorch?
Как только поняли принцип - сразу. NumPy-реализация не масштабируется: нет GPU-ускорения, нет автоматического дифференцирования, нет готовых слоев. Для реальных проектов берите PyTorch (гибче, популярен в исследованиях) или Keras (проще API, быстрее прототипировать). Реализация с нуля - это учебный тренажер, не продакшн-инструмент.
Следующий шаг - возьмите реальный датасет (например, MNIST с рукописными цифрами) и перепишите эту же сеть на Keras: сравните, сколько кода уходит на то же самое. После этого имеет смысл изучить свёрточные сети (CNN) для работы с изображениями - это логичное продолжение того, что вы только что построили.
Мнение редакции ENGRAM
Рекомендуем начинать именно с этого пути: сначала реализовать backpropagation вручную на NumPy, и только потом переходить к PyTorch - он доступен из РФ без VPN и устанавливается одной командой. Google Colab для GPU оплатить из России затруднительно, поэтому на этапе обучения используйте локальную машину: для задач уровня XOR и небольших датасетов CPU более чем достаточно. На нашем опыте именно понимание градиентного спуска "изнутри" принципиально меняет качество работы с готовыми моделями - без этого фундамента тонкая настройка корпоративных решений превращается в угадывание.
Источники¶
Материал подготовлен на основе:
- Build a Neural Network from Scratch in Python | Let's Data Science
- Constructing Neural Networks From Scratch: Part 1 | DigitalOcean
- Neural Networks From Scratch: A Developer's Guide | Nerd Level Tech
- Building Neural Networks From Scratch A Step-by-Step Guide | Ahammad Nafiz
- Neural Network From Scratch: A Python Guide
- Build Your First Neural Network - by Ramakrushna
Нейросеть на ваших встречах, документах и переписке: отвечает со ссылкой на источник. Это ваша вторая память на базе ИИ. Данные хранятся в России, старт бесплатный.
Зарегистрироваться бесплатноENGRAM запоминает ваши встречи, документы и переписку и мгновенно находит ответ со ссылкой на источник. Ваша вторая память на базе ИИ. Данные в России, старт бесплатный.
Зарегистрироваться бесплатно